
前面介绍了SDK安装过程和注意事项,下面我们简单介绍下SDK的主要结构和功能。如果你有开发经验的化,一定知道SDK中API的重要性。这不但为我们节省了很多通用的功能的实现,也可以让我们关注在汽车的具体功能上的开发。并且可以得到强大的程序。
本文对一些API做一些介绍,具体可以查询SDK库。
Hexagon SDK主要功能和结构介绍
Qualcomm的Hexagon SDK让开发者能够在Hexagon DSP上运行的代码,是通过Computation Offload来实现的. Computation Offload是将计算工作卸载到DSP上进行. 而且令人振奋的是application DSP、compute DSP、modem DSP和Sensors Low Power Island都能实现计算工作卸载的功能。这需要Fast RPC和Dynamic loading来实现这个过程.
FastRPC是CPU和DSP链接交互的桥梁。Dynamic loading是指Hexagon SDK提供的通过动态共享对象在DSP上创建和执行自定义代码的工具和服务.
所有需要安装的工具都在Hexagon SDK的tools目录下.
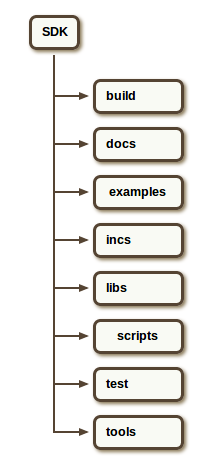
上图是SDK目录结构图:
目录build:包括cedp等,make.d的文件
目录docs:包括Hexagon SDK的文件信息
目录examples:包括一些例子,可以用来作为了解这个SDK的起点来做更先进的音频,动态和FastRPC模块
目录incs:示例或库使用的一些头文件
目录libs:可运行在应用处理器工具库和工具
目录scrips:包含实用脚本
目录test:一些用来测试Hexagon DSP模块的基础
目录tools:新建实例的工具集,Android NDK,Hexagon 工具,Hexagon IDE,签名,调试和一些其他工具
HVX矢量计算及机器学习
HVX: 全称Hexagon Vector Extensions,是一种能有效地实现低功耗和高性能的以处理像素为基础的算法,适用于相机,计
基于HVX的计算机视觉: SDK包含了几个例子,图算机视觉和视频处理.
像处理应用程序演示等,都是用Hexagon DSP来实现计算机视觉,这些例子可以更广泛地用于各种目的的卸载计算应用到Hexagon DSP中处理.
基于HVX的机器学习: 机器学习探索的研究和构建算法,可以学习和预测数据.这样的算法操作,通过示例输入建立一个模型来做数据的预测,而不是严格遵循静态程序指令.可升级的骁龙架构让其能够被应用到低功耗的可穿戴设备之类,完全链接的手机设备之类.这些设备有不同的计算能力和连接能力,适用于各自环境如:不同的电源限制如插入或不操作,不同的可靠性要求如连续运行5年,安全要求如OEM代码的执行.骁龙架构的一个重要组成部分就是Hexagon DSP,随着Hexagon DSP的扩展,低功耗设备机器学习可以用于新的应用.
基于HVX的部分API
这里我们介绍一下SDK中一些示例,即在HVX上实现的一些算法。
线性回归是一个变量Y和一个或多个变量X之间的关系建模方法,属于监督学习范畴.基于HVX的线性回归的设计和API函数的设计. 参考代码在目录examples/machine_learn-ing/LinearRegression中。
线性回归的实现主要通过Cost function和梯度下降来实现。
Cost Function有助于找出适合数据的最佳直线,也有助于决定theta(i)参数的值,不同的值会得到不同的函数.基于训练集,我们需要得到的直线的参数使得htheta(x)逼近于y. Cost Function有助于解决一个最小化问题,使得htheta(x)和y的差的平方最小化,也使得训练集中的所有h(x)和y之间的差最小化.
HVX的Cost Function的API:
void computeCostHVX16(int16_t* input,
// Signed 16 bit input vector which needed to be scaled down
int16_t numTrainingSet,
// Length of training set
int16_t numFeatures,
// Number of input features
int16_t* output,
// Output Collected
int16_t* theta,
// Theta vector
int16_t* costJ,
// Cost Function. This would be output from the function.
int16_t inputQformat
// Input Q Format. n of Qm.n format
)
输入跟输出都是标准的数量,是训练设置VLEN的倍数,如果不是就补充0来使之是VLEN的倍数.
梯度下降: 梯度下降算法有助于收敛到最小的θ,算法如下:

需要反复执行直到相等:
HVX 的梯度下降的API:
void computeGradientHVX16(int16_t *restrict input,
// Input Training Data Vector in appropriate Q Format
// Ensure that this vector is memaligned with VLEN
int16_t numTrainingSet,
// Number of data points used for training
int16_t numFeatures,
// Number of features
int16_t *restrict output,
// Output Training Data Vector in appropriate Q Format
// Ensure that this vector is memaligned with VLEN
int16_t *restrict theta,
// Initial Theta for computing cost.
// This should be provided in appropriate Q Format
// Ensure that this vector is memaligned with VLEN
int16_t* grad,
// Gradient for respective iteration
int16_t inputQformat,
// Input Q format
// Output will also be in same Qformat
// n of Qm.n format
int16_t lambda
// Regularization Parameter
);
训练集的数量要求是VLEN/2,如果不是VLEN/2的个数,就填充0让他是.
介绍完Cost function和梯度下降,我们重点看下线性回归。
线性回归:
计算Cost和梯度同时收敛到局部极小,输出的alpha和λ就是我们需要的.
算法: 初始化theta;
重复{
用theta计算cost
用theta计算梯度
更新theta:theta=theta-(alpha(multiply)grad)
}
HVX 的线性回归API:
void linearRegressionSingleLambdaAlphaHVX16(
int16_t *restrict input,
// Input Training Data Vector in appropriate Q Format
// Ensure that this vector is memaligned with VLEN
int16_t numTrainingSet,
// Number of data points used for training
int16_t numFeatures,
// Number of features
int16_t *restrict output,
// Output Training Data Vector in appropriate Q Format
// Ensure that this vector is memaligned with VLEN
int16_t* theta,
// Initial Theta for computing cost.
// This should be provided in appropriate Q Format
// Ensure that this vector is memaligned with VLEN
int16_t* costJ,
// Cost for respective iteration
int16_t* grad,
// Gradient for respective iteration
int16_t inputQformat,
// Input Q format
// Output will also be in same Qformat
// n of Qm.n format
int16_t lambda,
// Regularization Parameter
// This should be provided in appropriate Q format
int16_t alpha,
// Factor to converge to minima
// This should be provided in appropriate Q format
int16_t num_iteration
// Number of iterations for which convergence should
// be executed
);
线性回归的验证曲线:
对于任何机器学习算法,将数据集分成训练数据和交叉验证数据.同样的对于线性回归,我们需要50%个数据的训练和50%个数据交叉验证.costs值的比较有助于决定正则化参数.
算法:
初始化theta{
生成线性回归模型(alpha,lambda)
用模型计算cost做测试数据
用模型计算cost做验证数据
}
HVX的交叉验证API:
void validationLinearRegressionHVX16(
int16_t *restrict input,
// Input Training Data Vector in appropriate Q Format
// Ensure that this vector is memaligned with VLEN
int16_t *restrict inputVal,
// Input Validation Data Vector in appropriate Q Format
// Ensure that this vector is memaligned with VLEN
int16_t numTrainingSet,
// Number of data points used for training
int16_t numValidationSet,
// Number of data points used for validation
int16_t numFeatures,
// Number of features
int16_t *restrict output,
// Output Training Data Vector in appropriate Q Format
// Ensure that this vector is memaligned with VLEN
int16_t* outputVal,
// Output Validation Data Vector in appropriate Q Format
// Ensure that this vector is memaligned with VLEN
int16_t* theta,
// Initial Theta for computing cost.
// This should be provided in appropriate Q Format
// Ensure that this vector is memaligned with VLEN
int16_t* costJ,
// Cost
int16_t* grad,
// Gradient
int16_t inputQformat,
// Input Q format
// Output will also be in same Qformat
// n of Qm.n format
int16_t num_iteration,
// Number of iterations for which convergence should
// be executed
int16_t *alpha,
// Factor to converge to minima
// This should be provided in appropriate Q format
uint32_t sizeAlpha,
// Size of data pointer of Alpha
int16_t *lambda,
// Data pointer to Regularization Parameter
// This should be provided in appropriate Q format
uint32_t sizeLambda
// Size of data pointer of Lambda
)
Qualcomm汽车技术讨论组 QQ群号:566131670

