视频

众所周知,软件开发极为重要,在整个项目的成本中占比在60%-70%。
ARM Cortex-A系列处理器内核(A57、A53)在高性能细分市场中享有盛名,例如智能手机、机顶盒以及网络的应用处理。如果把目光转向电子市场,你会意识到很多应用程序对于成本极为敏感,且不需要这样的高性能处理器内核。我们将之称为嵌入式市场,但这一定义仍然比较模糊。ARM Cortex-M家族针对不同细分市场开发各类产品,从价格最低的Cortex-M0,功耗性能最平衡的Cortex-M3,到使用需要数字信号处理(DSP)功能应用程序的Cortex-M4,各不相同。
在音频、声控、物体识别,汽车和更高端的物联网感应的复杂传感器融合领域,音视频的复杂算法是保证音视频功能的必要前提,这时便需要Cortex-M7。ARM提供处理器内核和紧密耦合内存(TCM)架构,但诸如Atmel的ARM被许可方需要以特殊的方式实现内部存储,从而保证用户完全利用M7内核,满足系统性能和延迟目标。
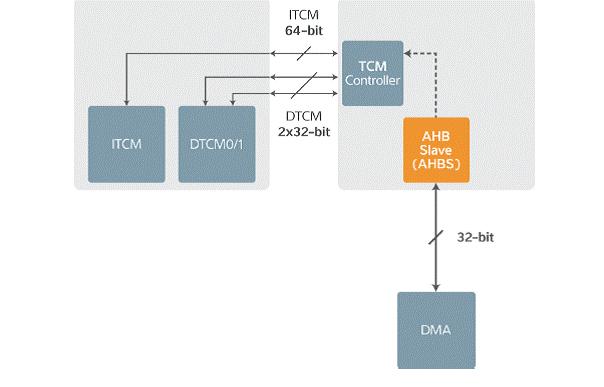
TCM接口提供一个64位指令端口和两个32位数据端口。
在一个65nm级的嵌入式闪存处理设备中,Cortex-M7可实现1500的CoreMark评分,且运行频率保持在300MHZ,保证顶级的DSP性能:双倍精确的浮点运算单元和成对发布指令流水线。但FIR、FFT或Biquad等算法需要尽可能确定运行,从而实现实时响应或无缝的音视频性能。你该如何正确选择内存,从而支持保证该性能?如果你选择闪存,这需要超高速缓存(原因在于闪存太慢),从而导致缓存缺失风险。静态随机存取内存(SRAM)技术是更好的选择,原因在于其可轻易嵌入芯片中,且允许以处理器的速率随机存取。
在通用系统SRAM中设置的外围数据缓冲区一般由直接内存存取(DMA)传送从系统外围加载。然而,从多个源加载数据的能力会导致不必要延迟和多个DMA试图同时存取内存时发生冲突的可能性增加。在一个典型的案例中,我们可能有三个不同的实体竞争直接内存存取SRAM,包括一个处理器(64位存取,该案例要求128位)和两个独立的外围DMA请求(分别为DMA0 和DMA1,32位存取)。Atmel通过将SRAM分为多个区位解决这一问题,如下图所示:
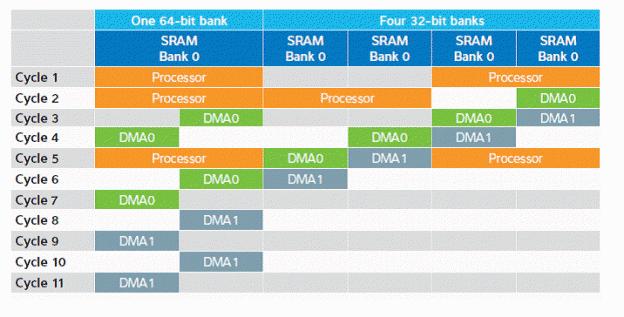
通过将SRAM调配为多个区位,多DMA脉冲能够同时出现,且延迟降至最低。
对于设计微控制器的芯片制造商而言,许可ARM Cortex-M处理器内核能够实现诸多优势。第一点便是ARM内核价格的普遍性,其在多个细分市场中皆被采用,支持众多应用程序。如果芯片制造商希望将设计导入到新客户中,很可能该原始设备制造商已经采用了基于ARM的微控制器,且很重要的一点是,该原始设备制造商能够重复使用已有的代码(众所周知,软件开发极为重要,在整个项目的成本中占比在60%-70%)。但这一普遍性也带来了挑战:如果竞争对手能够许可完全一样的处理器内核,你如何从中脱颖而出?
一种方法是选择更具侵略性的技术节点和以更低的成本提供更高的性能,但我们认为一旦竞争对手也选择这种节点,这种优势将荡然无存。另一种方式是集成更多的闪存,这在产品技术设计能够保证价格足够低时极为有效。
如果芯片制造商设计出了更具侵略性的技术节点以提供更高的性能,且比竞争对手提供更多的闪存,他便有可能脱颖而出。加上更为智能的内存架构,不受缓存缺失、中断、线程交换或其他影响确定定时的执行意外的影响,便能够具有极大的竞争优势。
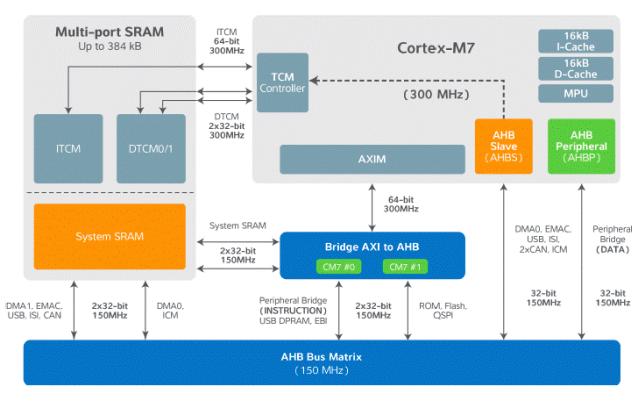
如果您希望更为透彻了解Atmel如何为Cortex-M7设计该智能内存架构,我推荐你看一看Jacko Wilbrink和Lionel Perdigon写的《Cortex-M7紧耦合内存,让算法飞起来》白皮书(你需要注册)。该白皮书阐述了如何将微控制器和分为四个区位的SRAM集成,从而作为通用SRAM,适用于紧耦合内存。这说明Cortex-M7微控制器可安装在Atmel | SMART SAM S70、SAM E70、以及SAM V70/V71产品系列中。
本文经SemiWiki.com允许转载,Eric Esteve为该网站的主要博主,以及四位创始人之一。本博客最初发表于2015年8月6日。